1 Project Overview
1.1 Goals
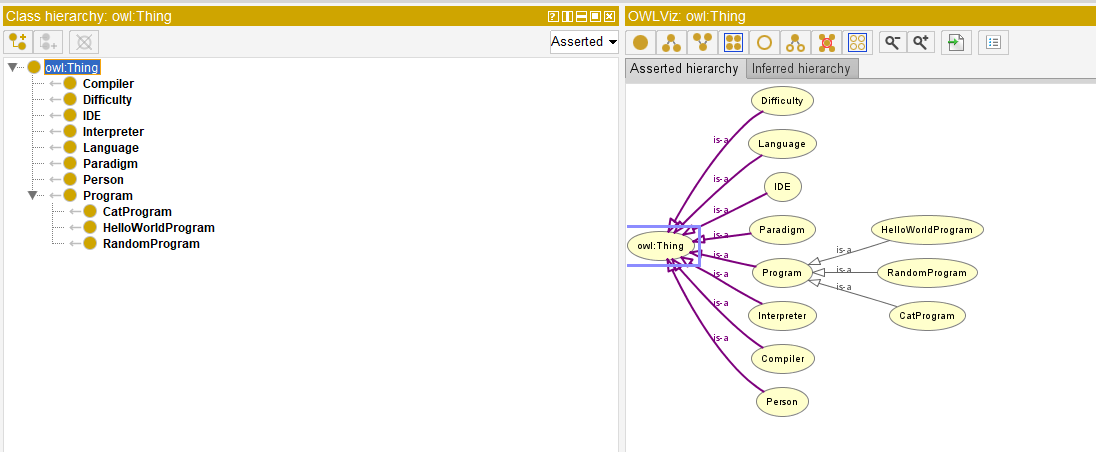
The ELA (Esoteric Language Explorer) application wants to give to anyone who thinks that has a uncommon way of thinking a challenge by providing all the possible information about esoteric programming languages.
Our progress can be followed here, on the blog: ELA blog
1.2 Structure
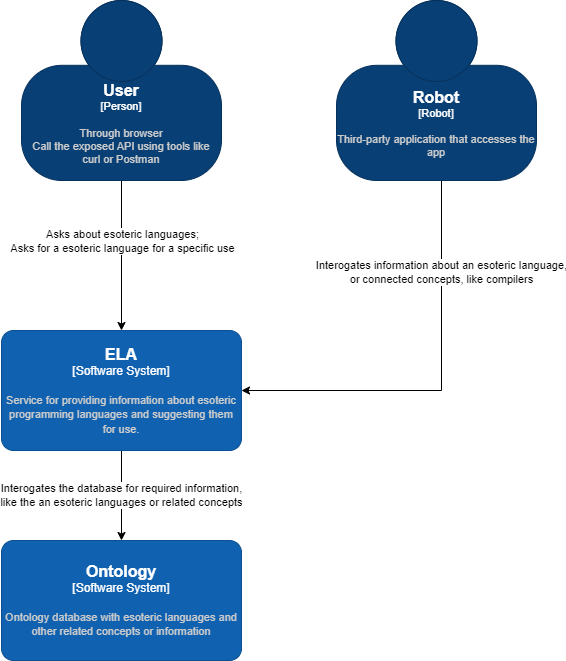
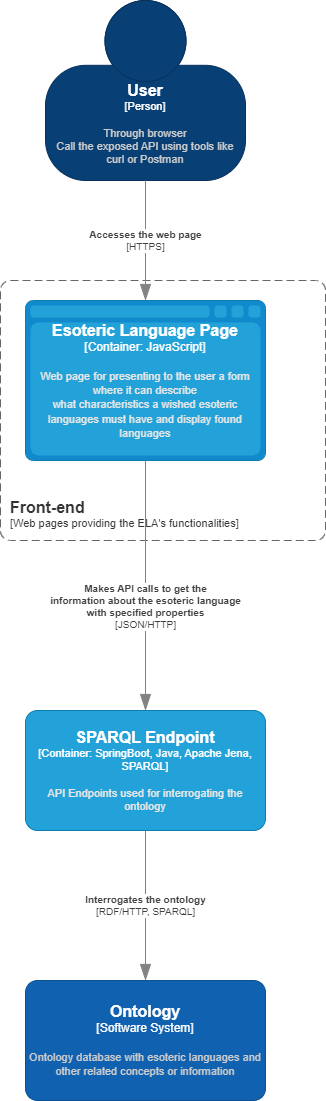
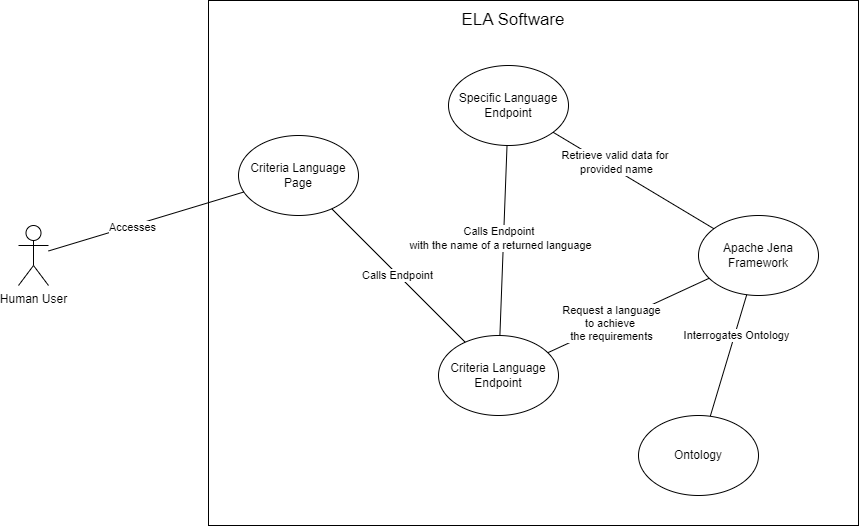
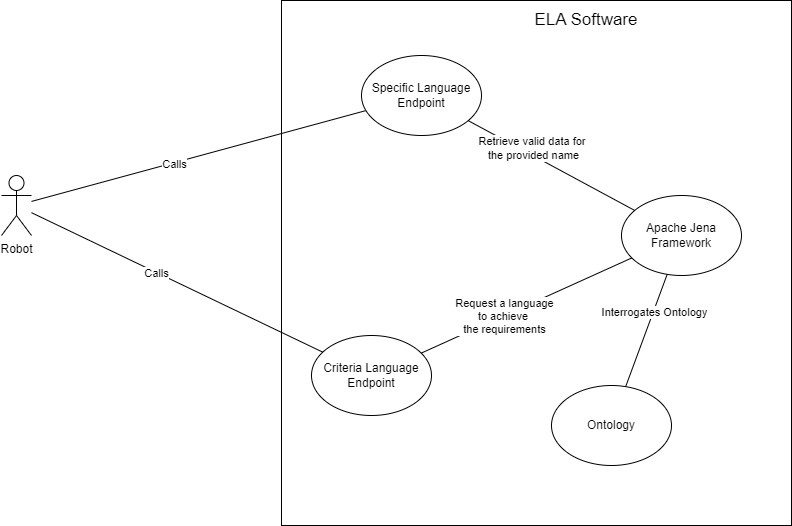
The application consists of a 1-page web interface and a public SPARQL endpoint. The web page is designed for the human users, and the API can be accessed by other applications.
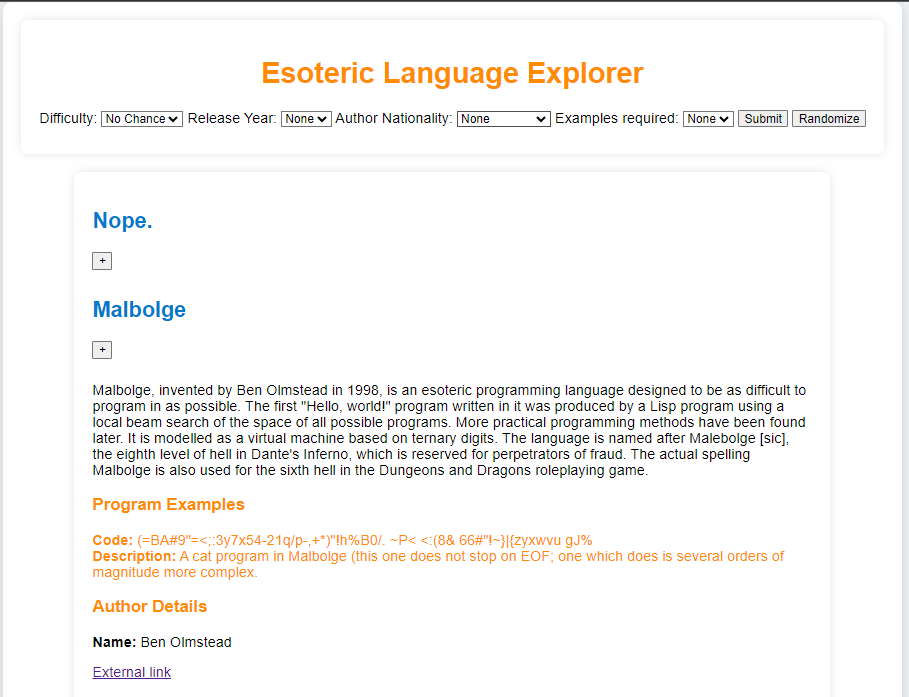
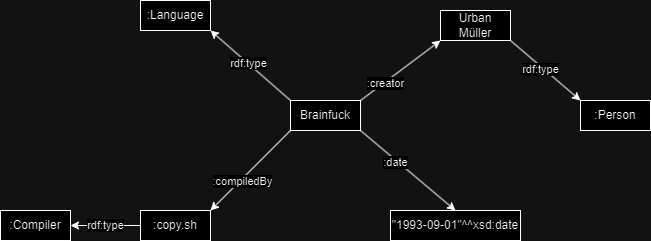
The main pages is for completing a form where the user can decide what criteria should be fulfilled by an esoteric language. For example, the user wants to know about difficult esoteric languages, or esoteric languages that are based on Brainfuck. The list of criteria is dynamic, this means that the user will be able to select/unselect items from the criteria list that is sent to the application.
The main page also has the option to generate random data to be sent to be web application in order to receive random languages.
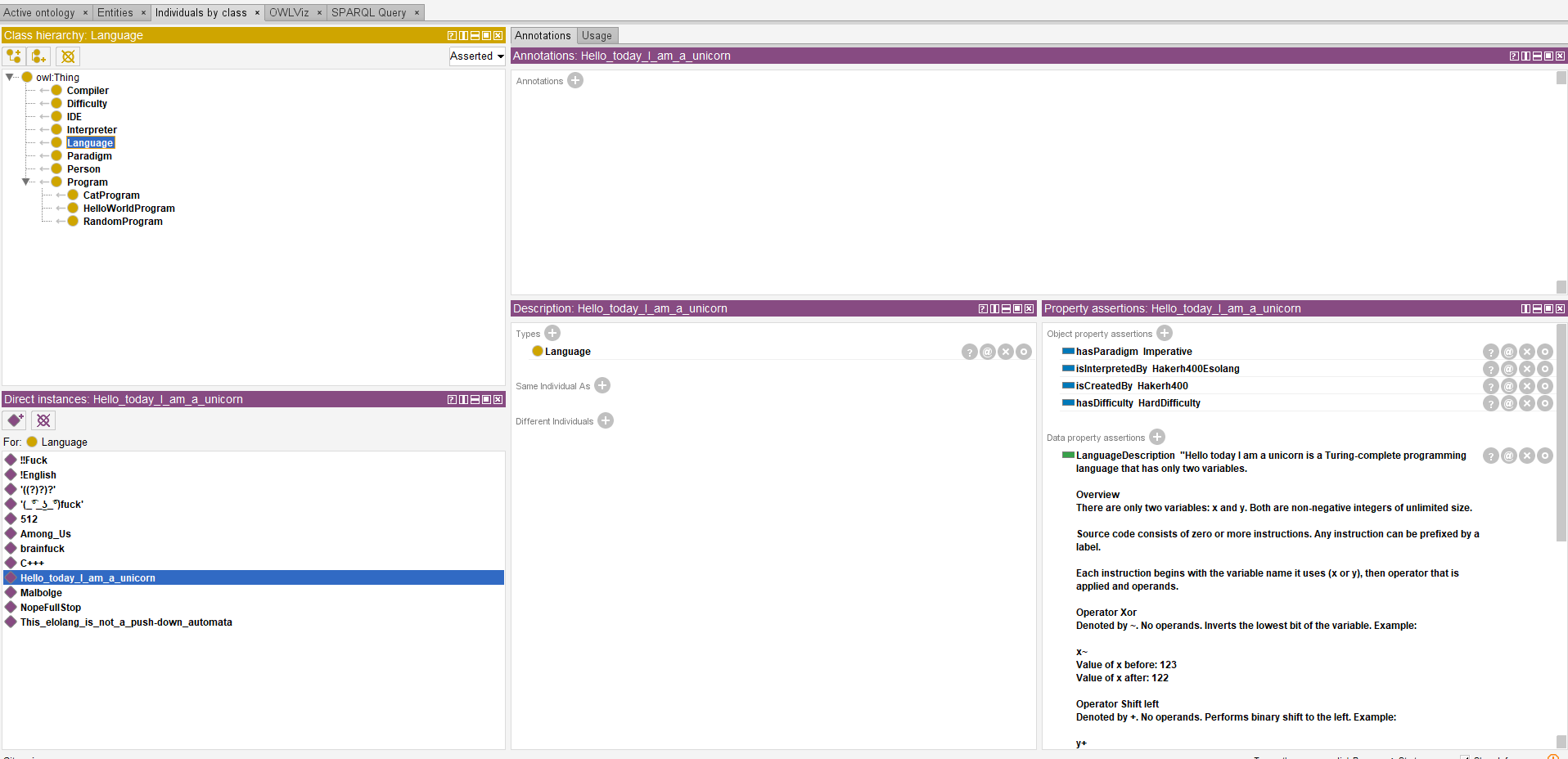
For a received language, the interface will display in the first phase a summary of the language, like the name. The user will have access to extend the information displayed in the interface.
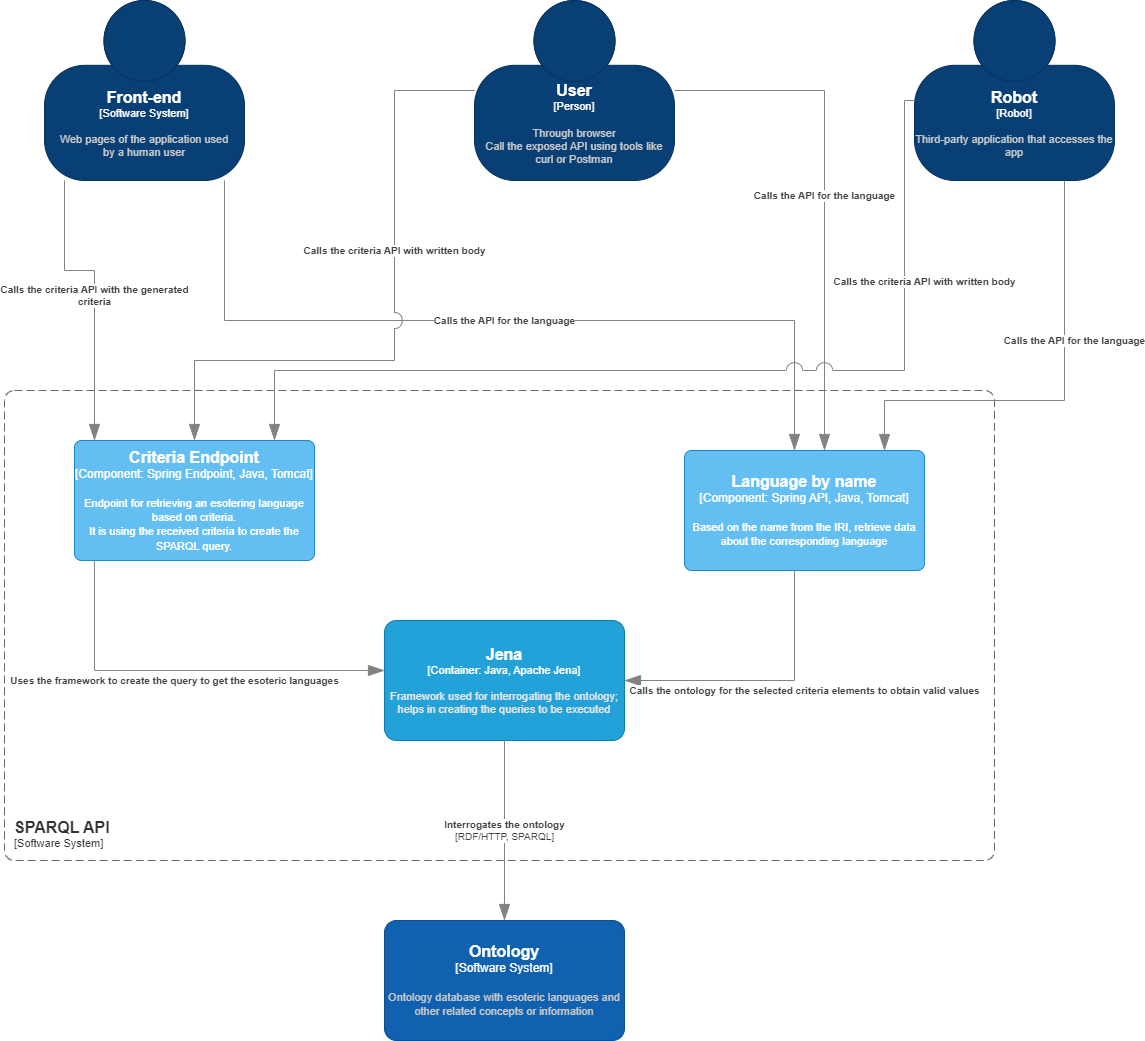
The SPARQL component represents a public endpoint that can be accessed by anyone. This endpoints provides two functionalitites:
- Retrieve a list of esoteric languages that meet all the criteria/ requirements
- Retrieve information for a specific esoteric language
A generic view of the application is as followed: